-
Paper Information
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Advances in Computing
p-ISSN: 2163-2944 e-ISSN: 2163-2979
2015; 5(1): 1-8
doi:10.5923/j.ac.20150501.01
Real Time Secure Video Transmission Using Multicore CPUs and GPUs
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-text HTML
Full-text HTMLK. Ganesan1, Jerin Geogy George2, Nithin P. V.2
1TIFAC-CORE in Automotive Infotronics and School of Information Technology and Engineering, VIT University, Vellore, India
2TIFAC-CORE in Automotive Infotronics, VIT University, Vellore, India
Correspondence to: Jerin Geogy George, TIFAC-CORE in Automotive Infotronics, VIT University, Vellore, India.
| Email: |  |
Copyright © 2015 Scientific & Academic Publishing. All Rights Reserved.
The main difficulty in implementing security to real time videos is the processing time. Processing time is considerably high while ensuring security using single core processors. This paper is analyzing the processing capability of Multicore CPUs and GPUs to facilitate a secure video transmission. Six different techniques using spatial and frequency domain are implemented using these systems. Adjacent frames are secured using different techniques to improve security. The processed video is transmitted over LAN to a neighboring system to see whether a real time reproduction is possible or not. The paper also compares the processing time for real time as well as stored videos, with varying resolution. In the case of real time video security, GPU system was able to transmit 23 frames per second while single core CPU system was able to transmit only 2 frames per second. Multicore CPU system with 8 cores was able to transmit 8 frames per second. The resolution of the video transmitted was 320 x 240. When just security techniques were applied (video not transmitted) on a stored video of resolution 640 x 480, the performance of GPU system was 38.3 times better than single core CPU system and 7.7 times better than multicore CPU system.
Keywords: Video security, CUDA GPU, Multicore, Video processing
Cite this paper: K. Ganesan, Jerin Geogy George, Nithin P. V., Real Time Secure Video Transmission Using Multicore CPUs and GPUs, Advances in Computing, Vol. 5 No. 1, 2015, pp. 1-8. doi: 10.5923/j.ac.20150501.01.
Article Outline
1. Introduction
- Cryptography is a method of protecting the information from undesirable persons by converting it into an unrecognizable form. With the advent of smart phones, tablets and other electronic gadgets, video calling is gaining more popularity. Many airborne surveillance cameras are being used for commercial as well as military purposes. Massive accumulation of data invites users to store data in cloud storage systems. In all these cases sensitive information is being transmitted from one place to another. Video-on-demand is another area where security is needed to prevent unauthorized people from accessing the video. Regarding the protection of video, which may be containing many frames per second (fps), the two techniques that are widely employed are scrambling and encryption. In scrambling, the pixel values of the image are swapped between the indexes whereas in encryption the pixel values are modified with some algorithm. To avoid high processing time normally scrambling is employed to provide protection to videos. Standard encryption algorithms could provide better security but at the cost of processing time [1, 2].Parallel computing is a form of computing in which many operations are carried out simultaneously. Since the processing time has become an important factor in all computations, parallel computing platform is getting wide acceptance. Parallel computing platform can be based on Central Processing Unit (CPU) or Graphics Processing Unit (GPU). CPU based parallel computing can be accomplished through Multi-core systems, Multiprocessors, Computer clusters, Grid computers etc. GPUs are normally used for video rendering and graphics enhancement. But now GPU manufacturers have developed new platforms which enable GPU for more general purpose usage, not just for graphics or videos. Compute Unified Device Architecture (CUDA) programming developed by NVIDIA facilitates the GPUs for general purpose computing. Most of the modern computers, smartphones, tablets etc. are having multiple cores and many of them also contain GPUs. So the opportunity for parallel computing in modern digital world is vast [3-5].This paper studies the feasibility of using Multi-core CPUs / GPUs to transmit a secure real time video and reproduce it at the receiving end without considerable delay and jitter. Different security techniques in spatial and frequency domain are applied on adjacent frames in order to improve the security. The paper conducts a comparative study between the performance of single core CPU, multicore CPUs and GPUs on the basis of the computation performed. The computation is increased by increasing the resolution of the video to be processed. The paper also analyses the possibility of incorporating encryption techniques to secure real time videos.The organization of the paper is as follows: In Section II, the methodology adopted for securing the videos using parallel computing is elaborated in detail. In Section III, the focus is on the results obtained. Finally, in section IV we enumerate our conclusions.
2. Methodology
- The major steps involved in the secure video transmission are as follows.• Capture a real time video or open a stored video.• Extract each frame from the video.• Scramble/encrypt the pixels in the frame using Multicore CPUs / GPUs.• Transmit the processed frame to the client. • Unscramble/decrypt the pixels of the received frame.• Display the frame in real time or save the frame into a video file.If the frames are displayed at a rate higher than the persistence of vision then the video can be shown in real time. This depends on both the transmission time and the processing time. Video is transmitted from the server to the client through Local Area Network (LAN) using socket programming.
2.1. GPU Based Parallel Computing
- In order to process the frames using Graphics Processing Unit (GPU), Compute Unified Device Architecture (CUDA) library functions are used in the code which is programmed using C language. CUDA is a parallel computing platform developed by NVIDIA for general purpose GPU computing [6]. Image processing operations are performed using OpenCV library functions.CUDA program allows us to use both CPUs and GPUs in one program. Part of the CUDA program written in C language runs in the CPUs (Host). The other part of the program runs in GPUs (Device) in parallel which is also written in C language but with some extensions to express parallelism. CUDA compiler compiles the code and splits it into pieces to be run on CPUs and GPUs. CUDA considers GPU as a coprocessor to the CPU with both of them having separate memories. CPU runs the main program and controls all the actions of GPU [6-8]. The major operations involved in a CUDA program are• Moving the data from CPU memory to GPU memory.• Allocating GPU memory.• Invoking programs (kernels) in GPU that compute in parallel.• Moving the data from GPU memory to CPU memory.The part of the code which is to be parallelized using GPU is written as a device kernel. The codes inside the kernel get executed in parallel using multiple threads. The kernel is written in such a way that only a single thread is executing at a time. Kernel does not mention any thing about the level of parallelism. The number of threads that should be executed in a kernel is specified by the kernel call function. The maximum number of threads and blocks that can be scheduled depends on the compute capability of GPU. The threads are arranged in blocks in order to obtain high performance. The kernel is called from the host and is executed in the device. Before calling the kernel the data required for the operation is copied from the host memory to the device memory. The device memory is allocated according to the size of the data encountered. When the device finishes the calculations, the result is copied back from the device memory to the host memory. Thus the serial portions of program are run on CPUs and the parallel portions are run on GPUs [7, 8].
2.2. CPU Based Parallel Computing
- In order to use parallelism using multiple cores, Open Multiprocessor (OpenMP) library functions are used in the code programmed using C language [3, 9]. Image processing operations are performed using OpenCV library functions.OpenMP facilitates only user defined parallelization. User specifies the action to be taken by the compiler and system runs the program in parallel. Some compiler directives are used for this purpose. OpenMP constructs will not check for data dependencies, data conflicts, race conditions, deadlocks or any other situation that may give error output from the program. User should use the constructs carefully to avoid all these situations. Mainly, the parts of the code which contain loops with high iteration are parallelized [9, 10].OpenMP program begins with a single thread (main thread) of execution. The parallel construct is added above the loop body which is to be parallelized. When the main thread encounters the parallel construct, it creates a team with additional threads. The number of threads to be created is mentioned in the construct [9]. The number of threads cannot exceed the maximum number of logical processors in the system. The task inside the parallel region is split among the threads. Each of the thread has a thread private memory and shared memory. At the end of the parallel construct only the master thread resumes the execution. There is an implicit barrier for all the other threads by the end of the construct [9, 10]. Only the loops that do not cause any data conflicts are parallelized using the above mentioned method. All the variables used inside the loop are also made independent in order to avoid data dependencies.
2.3. Security Techniques
- Different spatial and frequency domain techniques are used to ensure security in the video. Adjacent frames are secured with different techniques to improve security. If all the frames in a video are secured using only a single technique, then it is easy to crack the security measures. The following are the various spatial and frequency domain techniques employed to secure the image frames in the video.
2.3.1. Arnold Transform
- Arnold transform is used to scramble the pixels in a frame in spatial domain. Arnold transform is a process of clipping, splicing and realigning the pixel matrix of digital image. The new indexes for the pixels are calculated using equation (1) [11, 12].
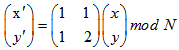 | (1) |
2.3.2. Cosine Transform Based Scrambling
- The pixels in the frame are transformed into frequency domain using discrete cosine transform. Two dimensional discrete cosine transform is used for this purpose. The general equation for a 2D cosine transform is defined by equation (2) and equation (3) [13].
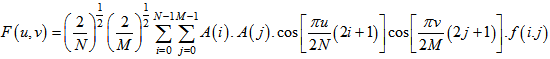 | (2) |
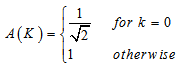 | (3) |
2.3.3. Fourier Transform Based Scrambling
- The pixels in the frame are converted into the frequency domain by FFT. In this domain some alterations are introduced and then the frame is converted back to the spatial domain. Before applying FFT, the single channel video frame is converted into two channel complex frame by adding a separate channel consisting of zeros. This is done because performing FFT will produce real values as well as imaginary values. Added channel is then used to store the imaginary values. The general equation for the 2D FFT used is defined by equation (4) [16].
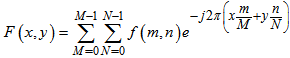 | (4) |
2.3.4. Cipher Block Chaining Encryption
- To encrypt the video using cipher block chaining, a look up table is created. To create the look up table an 8 dimensional cat map is used. It is given by the equation (5) and equation (6) [14, 18].
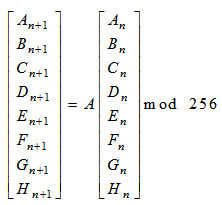 | (5) |
 | (6) |
2.4. Socket Program
- Socket program is used to transmit the secure video from the server system to the client system. Stream sockets which rely on TCP protocol to establish reliable connection is used for this purpose. The major steps involved in the data transmission are the following [19].• Create socket (stream socket) at both server and client systems.• Assign address to the sockets using bind function.• Server listens to any connection request using listen function.• Client uses connect function to request for a connection.• Server accepts the connection request using accept function.• Once the connection is established, send and receive functions are used to transmit the data. • Close function is used to stop the data transmission and to close the connection.Initially server and client systems are connected using a LAN cable. A local network is also established between the systems by manually setting the IP addresses.
2.5. Implementation
- To ensure security, RGB image frames are captured from the video. Then the three channel image is split into single channel R, G and B images. Then each of these single channel images is secured using one of the above mentioned techniques. The technique used is decided by the image frame number, N. N%6 is computed and the corresponding security technique listed in Table 1 is applied.
3. Results and Discussions
- The techniques mentioned above were tested using both real time and stored videos. The processing time for Multi-core CPUs and GPUs were noted down. The same techniques were employed by varying the resolution for both the real time and stored videos. At the server and client side 2 Intel Xeon processors each with 4 cores (Total of 8 cores) were used for multicore programming. The clock speed of the processor is 2.4 GHz. For GPU programming, at the server and client side TESLA C2050 GPUs with 448 cores were used. The clock speed of the GPU processor used is 1.15 GHz. The double precision floating point performance of TESLA C2050 is 515 Gflops. Its single precision floating performance is 1.03 Tflops.
3.1. Sample Image Frames of Processed Video
- The following figures show the sample image frames obtained when various security techniques were applied on the video.Figure 2 and Figure 4 is seen as three different portions. This is because of the memory coalescing technique applied in Arnold transform scrambling and Fourier transform based scrambling. Memory coalescing improves the processing speed by minimizing the time spent on memory accesses [7]. Even though the secured video is seen as three portions, the scrambling achieved is good. In Figure 3 and Figure 5 some shades of the original image is seen. But they do not reveal any information about the original image. When the cipher block chaining (CBC) encryption was combined with the cosine transform based scrambling, a completely unrecognizable image was obtained. This is seen in Figure 7. The combination of CBC encryption and Arnold transform scrambling also gave a good secured video. Figure 6 shows the image frame obtained on applying this technique.
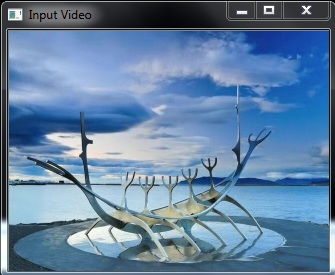 | Figure 1. Image frame of input video |
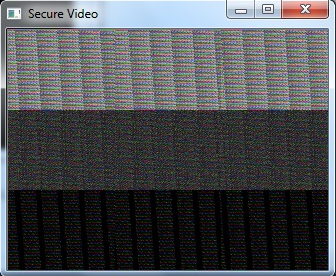 | Figure 2. Image frame of the scrambled video using Arnold Transform |
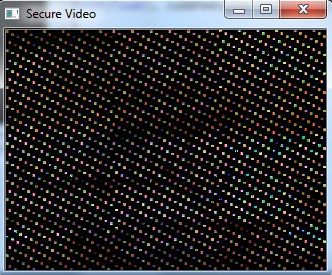 | Figure 3. Image frame of the scrambled video using Discrete Cosine Transform |
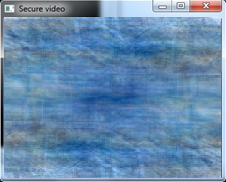 | Figure 4. Image frame of the scrambled video using Discrete Fourier Transform |
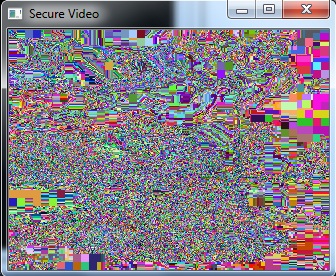 | Figure 5. Image frame of the encrypted video using Cipher Block Chaining encryption |
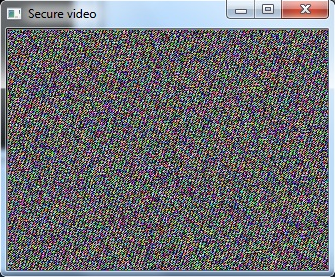 | Figure 6. Image frame of the secured video using Cipher Block Chaining encryption and Arnold Transform scrambling |
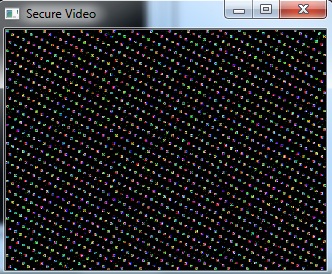 | Figure 7. Image frame of the secured video using Cipher Block Chaining encryption and Discrete Cosine Transform scrambling |
3.2. Comparison of Security Techniques
- The frames are secured basically using three scrambling techniques and an encryption technique. In the three scrambling techniques employed, one is in time domain and the other two is in frequency domain. Arnold transform scrambling, the spatial domain technique, is not as strong as the frequency domain techniques employed since there is no domain shifting. Arnold transform scrambling is also a very common digital image scrambling technique. But the processing time for implementing this technique is low compared to the other techniques.DCT scrambling and DFT scrambling are the frequency domain scrambling techniques used. Both techniques involve a shifting from time domain to frequency domain. But in DFT scrambling the image is converted into a two channel complex frame which again is split into magnitude and phase matrix. The scrambling is implemented by permuting the phase matrix. In DCT scrambling the scrambling is applied directly to the matrix obtain after converting to the frequency domain. So DFT scrambling is the secure technique comparing the two. But the processing time for this technique is more compared to the other.Scrambling involves just swapping of the pixels in a frame while encryption modifies the pixels in the frame. So the Cipher block chaining (CBC) encryption technique is far more secure than the scrambling techniques employed, but at the cost of processing time. In CBC encryption each pixel level is replaced with a value that is calculated using a complex algorithm. Hence the processing time is much more compared to the scrambling techniques. The last two techniques is a combination of the scrambling techniques mentioned above. These two techniques are the most secure techniques employed in this paper. CBC encryption plus Arnold transform scrambling involves an encryption and scrambling in time domain whereas CBC encryption plus DCT scrambling involves an encryption in time domain and then a scrambling in frequency domain.
3.3. Video Transmission
- The secured video is transmitted to another system in the network and the original video is reproduced in the client system using single core CPU, multi core CPUs and GPUs. The number of frames considered for experimentation was 100. The time delay added between consecutive frames have small effect on the time taken by the systems listed in Table 2. Figure 8 is a chart plotted using the time taken by the systems listed in Table 2 in their respective order.
|
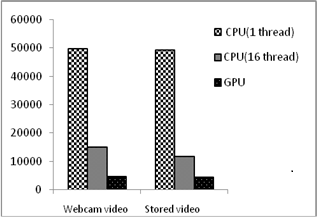 | Figure 8. Performance comparison of the systems |
3.4. Processing Time for Video with Different Resolution
- In this case the security techniques were applied in the similar manner, but the resolution of the video was varied each time. This experiment was carried out in order to analyse the performance variation of the systems when the computation encountered by them was increased. Here only the time taken for applying the security techniques was noted. The number of frames considered was 100. Table 3 lists the processing time taken by each system for different resolutions. Figure 9 is a graph plotted using data in Table 3 to illustrate the performance variation when the computation was increased.
|
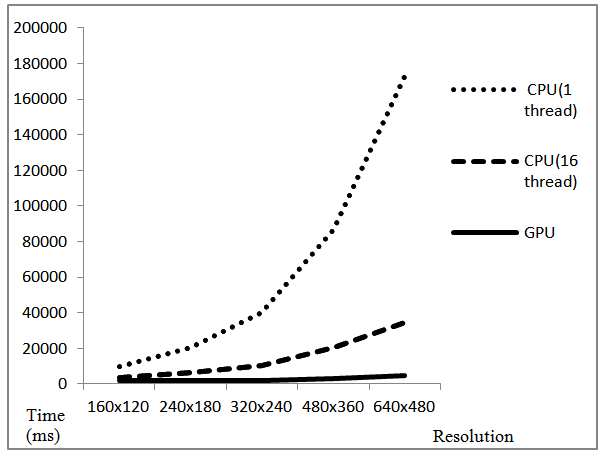 | Figure 9. Processing time vs Resolution |
|
4. Conclusions
- This paper analysed the processing capability of a multicore CPUs and GPUs to facilitate secure video transmission. Six different techniques in spatial and frequency domain were implemented using these systems. The secured video was transmitted over LAN to the neighbouring system and a real time reproduction was achieved.The analysis proved that it is also not suitable to apply encryption on video using single core systems. The processing time was very high and it caused a lot of lag when video is reproduced. But with the processing capability of GPUs and multicore CPUs, encryption technique was incorporated along with some scrambling techniques to secure real time videos. The whole process was parallelised using Tesla C2050 GPUs and Intel Xeon (8 core) CPUs.Applying security on real time videos is very difficult [21]. Even applying a simple scrambling technique on a real time video using single core system caused a lot of lag. With the help of GPUs and multicore CPUs, security was applied on real time videos. Parallelism using GPUs caused no lag whereas using multicore CPUs caused small lag which was very less compared to single core CPU. GPUs were able to transmit 23 frames of secured video per second while multicore CPUs transmitted 8 frames per second.An increase in speed by about 11 times was achieved using GPUs to that of single core CPU when security is applied on real time video. Speed improvement of GPU over 8 cores CPUs was around 3.3 times in the same case. The performance showed some difference when considering a stored video. Speed improvement of GPUs over single core CPU remained the same but only 2.7 times improvement was observed for stored video processing using GPUs over multicore CPUs.GPUs also showed better performance as the amount of computation was increased. Performance improvement was only 4.8 times over single core CPU when processing 160x 120 image frames. But it became 38 times when the resolution was changed to 640x480. So it can be concluded that it is always better to process high resolution videos using GPUs.
ACKNOWLEDGEMENTS
- The authors, in particular Jerin Geogy George and Nithin P V would like to acknowledge the TIFAC-CORE in Automotive infotronics at VIT University, Vellore, India, for providing the necessary hardware, software and technical support in successfully implementing the present work.
References
| [1] | Wenjun Lu, Avinash Varna, and Min Wu, 2011, Secure video processing: problems and challenges, Acoustics, Speech and Signal Processing (ICASSP), IEEE International Conference, 5856-5859. |
| [2] | Jie Shen, 2009, Privacy-protection in real-time video communication, Embedded Software and Systems, ICESS '09. International Conference, 217-220. |
| [3] | J. Reinders, 2007, Intel threading building blocks, O’Reilly, Media. |
| [4] | Song Jun Park, 2009, An analysis of GPU parallel computing, DoD High Performance Computing Modernization Program Users Group Conference (HPCMP-UGC), 365-369. |
| [5] | George R Desrochers, 1987, Principles of parallel and multi processing, Intertext Publications, McGraw-Hill. |
| [6] | NVIDIA, 2012, CUDA C programming guide PG-02829- 001_v5.0, http://docs.nvidia.com/cuda/cuda-c-programming-guide. |
| [7] | Thomas True, 2012, Best practices in GPU based video processing, GPU technology conference, San Jose California. |
| [8] | Pavel Karas, 2010, GPU acceleration of image processing algorithms, Centre for Biomedical image analysis. |
| [9] | OpenMP.org, 2006, The OpenMP API specification for parallel programming, http://openmp.org. |
| [10] | Ying Liu and Fuxiang Gao, 2010, Parallel implementations of image Processing algorithms on multi-core, Fourth International Conference on Genetic and Evolutionary Computing, pp.71-74. |
| [11] | Fei Chen, Kwok-wo Wong, Xiaofeng Liao and Tao Xiang, 1960, Period distribution of the generalized discrete Arnold cat map for N=2e, Information Theory, IEEE Transactions, Volume 59, Issue 5, 3249-3255. |
| [12] | Mao-Yu Huang et al. 2010, Image encryption algorithm based on chaotic maps, Computer Symposium (ICS), International, Tainan. |
| [13] | Anton Obukhov and Alexander Kharmalov, 2008, Discrete cosine transform for 8x8 blocks with CUDA, NVIDIA. |
| [14] | K. Ganesan, G. Harisha Reddy, Sindhura Tokala and Raghava Monica Desur, 2013, Chaos based video security using Multicore framework, American Journal of Computer Architecture, 2(1): 1-7. |
| [15] | Wenjun Zeng and Shawmin Lei, 2003, Efficient frequency domain selective scrambling of digital video. IEEE Transactions on Multimedia, Volume 5, issue 1, 118-129. |
| [16] | L. Deng, Yu C L., Chakrabarti C. and Kim J, 2008, Efficient image reconstruction using partial 2D Fourier transform, Signal Processing Systems, SiPS, IEEE Workshop, 49-54. |
| [17] | Arthur Gordon Mason, 1991, Video scrambling in frequency domain, Patent EP0406017 A1, Reese, L. C., and Welch, R. C, Lateral loading of deep foundations in stiff clay., J. Geotech. Engrg. Div., 101(7), 633–649. |
| [18] | K. Ganesan and S. Ganesh Babu, Chaos based image encryption using 8D Cat Map (unpublished, private communication). |
| [19] | Ming Xue and Changjun Zhu, 2009, The socket programming and software design for communication based on server/client, Circuits, Communications and Systems, PACCS ‘09. Pacific-Asia Conference, 775-777. |
| [20] | Ami Marowka, 2012 “Extending Amdahl’s law for heterogeneous computing”, Parallel and Distributed Processing with Applications (ISPA), IEEE 10th International Symposium, 309-316. |
| [21] | Gabor Feher, 2013, The price of secure mobile video streaming, 27th International Conference on Advanced Information Networking and Applications Workshops, 126-131. |