-
Paper Information
- Next Paper
- Paper Submission
-
Journal Information
- About This Journal
- Editorial Board
- Current Issue
- Archive
- Author Guidelines
- Contact Us
Advances in Computing
p-ISSN: 2163-2944 e-ISSN: 2163-2979
2011; 1(1): 1-7
doi: 10.5923/j.ac.20110101.01
Cube Index for Text and Image Information Retrieval and Mining
 Abstract
Abstract Reference
Reference Full-Text PDF
Full-Text PDF Full-Text HTML
Full-Text HTMLB. Janet , A. V. Reddy
Dept. of CA, National Institute of Technology, Trichirappalli, India
Correspondence to: B. Janet , Dept. of CA, National Institute of Technology, Trichirappalli, India.
| Email: |  |
Copyright © 2012 Scientific & Academic Publishing. All Rights Reserved.
This paper proposes a novel cube index for text and image information mining. Based on the study of text and image index used for information retrieval, this paper proposes that information mining on unstructured text and image data is possible from the index structures that exist already. The cube index merges the text and image index proposed earlier, into a single structure. This mimics the brain in its capacity to view the text and image data simultaneously and retrieve them together, according to the query need of the user. It will help in the indexing, retrieval and mining of both text and image data present in the document database. The online analytical processing (OLAP) over the cube index and concept hierarchy for the document and image are proposed. The operations that can be performed on the data cube are applied to the cube index to help with the retrieval and mining. The study gives a good guarantee that the model can be used for database analysis of text and image, based on the results from the retrieval experiment.
Keywords: Indexing Model, Information Retrieval, Image Retrieval, Text Mining, Cube Index, Data Mining
Cite this paper: B. Janet , A. V. Reddy , "Cube Index for Text and Image Information Retrieval and Mining", Advances in Computing, Vol. 1 No. 1, 2011, pp. 1-7. doi: 10.5923/j.ac.20110101.01.
Article Outline
1. Introduction
- The advent of computers and the development of low cost storage devices have caused explosive growth in the amount of data that are stored in the database every day. The data stored was primarily text in the previous century. Now, image, audio and video data are also stored as and when they are generated. This explosion increases the amount of stored data. To sift through and retrieve the needed information from the data is a herculean task. The data mining techniques have been used to mine useful information. Now, the information mined is so large that it is difficult to extract knowledge from it. For a simple search query, there is a large set of related data retrieved. This data has to be again sifted through to extract knowledge from it. This complex process can be simplified if the data retrieved is multimedia data, similar to the brain. This paper proposes a cube index model that will help with retrieval of text and image data together, in an effort to imitate the brain.
1.1. Highlights
- Data cube on unstructured text and image is the first of its kind to the best of our knowledge. It uses a three dimensional storage structure, for the index. The cube index model represents the image as a single value based on the distortion of the image when reconstructed with the codebook. Given a text input, this helps us retrieve the image based on a feature[1] of the image. Given an image, it helps to retrieve the images that are similar and also the documents in which they occur. The image and text data are combined in a single structure, to help with easy retrieval.
1.2. Motivation
- The human brain has the ability to store and retrieve millions of data over a period of time. The storage is such that image, text, audio and video data are together stored as an experience. This experience when remembered or recalled based on either textual information or images of the scene or voice tracks that were heard in that place or clips of video of that experience, is retrieved accurately. This is because the human brain retrieves the information from the single storage structure of the neurons. If a text of the name of a person is input, the picture of the face of the person immediately pops out. Given an audio clip, the lyric (as text) comes out with the picture of the person, who wrote the lyric. The brain correctly tells the description of the park where the incident happened. This is possible only if the storage structure is processed for both text and image data simultaneously. The human brain stores the data that it captures, as an experience in a single structure in the neurons and retrieves them as a rich set of features. It includes the text, image, audio and video data. All are stored together in the brain, to be retrieved according to the query of the user.Today’s search engines search and retrieve based on either text alone, or image features alone. There is a lack of an integrated structure in information retrieval that acts as a common base for all the different types of data. This creates the need for a single index structure to store text, image, and audio information. To include the image and text information in a single structure, the documents with text and image are considered. Another wonder of the brain is that it considers the images with the depth information in three dimension. This is not possible in computer vision as the computer reads information in two dimensions and stores all information in two dimensions. Thus, the need for a three dimensional storage was felt and the cube index model was proposed initially for text data[2,3] and then for images[4] too.
1.3. Related Work
- There are index structures[1,5-10] that are used to store the metadata about the database to facilitate faster retrieval. The direct Index[6], inverted index[6,7,9], word pair index[10] are some of the standard index structures in usage.Data mining is performed on image[11], text[2,3,12], audio and video[13,14] data separately. Then, the information is merged to find relationship between the mined data. The type of data and the type of mining varies. In[15], a multimedia data cube is used to represent the image for processing and mining of information from the image. It is based on various dimensions like the size of the image, width, height, date of creation, format type taken as various dimensions.The disadvantage of the multimedia data cube is that the attributes are set oriented and not single valued. Also the number of dimensions is very large, which is called the dimensionality curse[15]. Thus, there is a need to reduce the number of dimensions and represent the image as a fact based on some numerical function. A single index structure to store both the text and image information is proposed. To the best of our knowledge there is no index structure that can store both the text and image data together as a single structure. This paper proposes the combined text and image index structure as a cube index for retrieval and mining. The annotated image database used in object and concept recognition in CBIR by the department of science and engineering, university of Washington [16,17] is used for a pilot study to test the feasibility of the cube model, as it has both text annotations and images. The cube index is created and evaluated for this data. The annotated image dataset retrieval results and the cube materialization have given some promising results in support of the cube index model proposed.
1.4. Comparison of Text and Image
- A text document contains a group of words made up of alphabets or numerals. An image contains a group of pixel blocks. The smallest unit of a text document is an alphabet and for an image is a pixel. The word or pixel block contribute to the content of the document or image respectively. The different types of word combinations contribute to the meaning of the document. Different positions of pixels contribute to the shape in the image.
|
1.5. Structure of Text Documents
- Text Document consists of alphabets which form the words. The words are paired to form word pairs, which form the phrases. The phrases can occur together to form the sentences which in turn form the paragraphs. Paragraphs combine to form the document. The word pairs contribute to the meaning of the document.
1.6. Structure of Images
- An image consists of pixels that have integer values for RGB representation to denote its content. The pixels are grouped together as pixel blocks of 2x2 or 4x4 or 8x8 or 16x16 pixels. Each block is represented as a block vector.
1.7. Knowledge Discovery Process for Text and Image
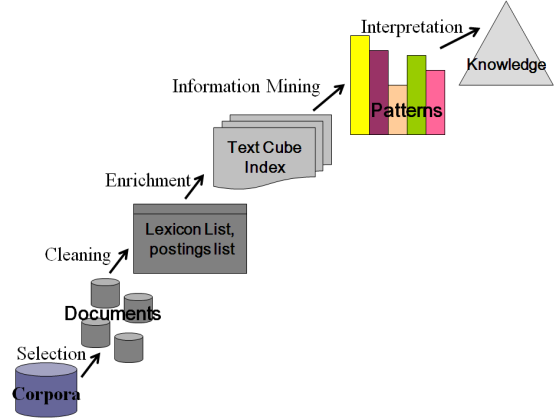
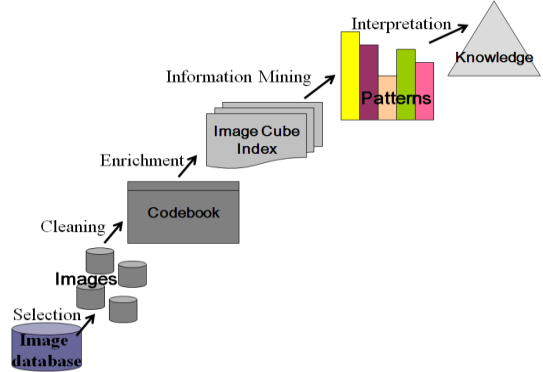
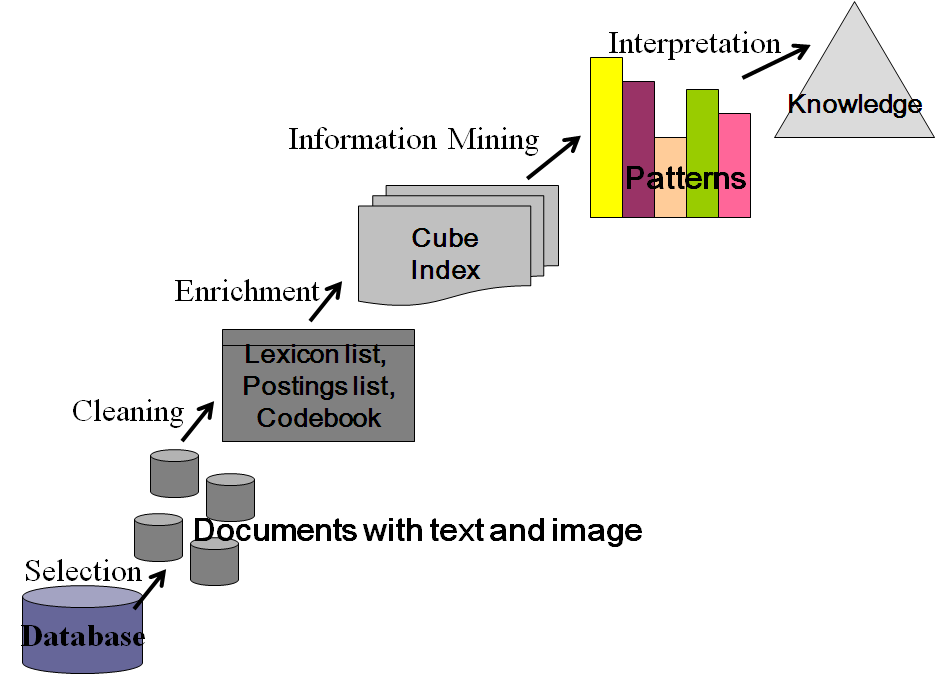
- The knowledge discovery process[15] is defined for data mining. This process is explained for text and image database as shown in Figure 1 and 2. The various stages of the KDD process are explained below for text and image data. The KDD for the combined text and image data is shown in Figure 3. The lexicon list and the postings list form the index of the database.
 | Figure 1. KDD for text. |
 | Figure 2. KDD for image. |
 | Figure 3. KDD for text and image. |
1.7.1. Cleaning
- A text document is preprocessed[6] to reduce the number of words and get the content words that contribute towards the meaning of the document. Stemming[23], stoplist[10], reducing the word to its common meaning[10], case folding [10] are some of the methods used to preprocess a document. This will help to reduce the size of the words that form the lexicon list, that represents the text document and not compromise on the meaning of the text. The postings list contains the position and frequency of the words.The image is first resized into a fixed size of width 512 x 512 to enable easier processing. It is converted into the 8-bit gray scale image as it captures the content of the image needed for retrieval and reduces the processing. The pixels of the image are grouped into block vectors of fixed size of either 2x2 or 4x4 or 8x8 or 16x16 pixels. Vector quantization[18,19,20] is used to quantize and compress the block vectors of pixels of an image. Using the LBG clustering algorithm[21], a codebook is computed for the image. The codebook consists of a set of codevectors that includes some semantic information.
1.7.2. Enrichment
- Enrichment results in processed data. The content of the corpora is represented as words or word pairs that are stored as direct or inverted or next-word index. The index holds the location and frequency information of the word pair in the document and is used to create a cube index from the postings list and the lexicon list. The cube index works as a direct or nextword or inverted index structure for text data. The image cube index is represented as a code book or codevector or block vector dimensions for the image.
1.7.3. Mining
- The cube index can be used for retrieval, clustering, classification and annotation applications.
2. Data Cube
- In Data Mining, a data cube[22] allows data to be modeled and viewed in multiple dimensions. It is defined by dimensions and facts. Dimensions are perspectives or entities with respect to which data is stored. Facts are numerical functions computed by aggregating the data corresponding to respective dimension-value pairs. Online analytical processing can be done efficiently on a data cube. The dimension hierarchy[15] is defined for a data cube with the operations roll up, drill down, slice, dice, and pivot.
2.1. Text Cube Index Model
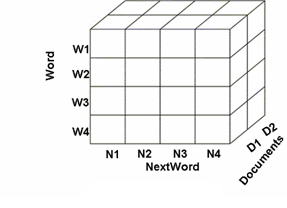
- Data cube has been created for various data like graphs[31], sequence data[24], spatial data[29], mobile data[25], structured[15] and semi structured[12] text data. But, work on unstructured text has not been possible because the textual data could not be quantized. In previous research, text mining approach referred to a multidimensional text database[15] where structured data and narrative text were considered. A text cube[12] was explained for semi structured data with term hierarchy and two operators push up and pull down. The measures considered were term frequency and inverted index. Later, the text index cube[2] with OLAP operations in document hierarchy to analyze unstructured text data was proposed. It allows unstructured text data to be modeled and viewed as shown in Figure 4. Dimensions are represented as Word, Next-word, and Document in which the phrase occurs. Fact is Term Frequency. Concept hierarchy for document[3] is defined for the word dimension with two operations scroll up and scroll down. A wordpair index[10] is used to create a cube index, for a set of documents. The wordpair index forms the cube direct index[10]. The cube direct index is pivoted to form the cube inverted index[10]. It is found that the cube index works for an experimental set of text corpora. It can be materialized from the already existing index structures.
 | Figure 4. Text Index Cube. |
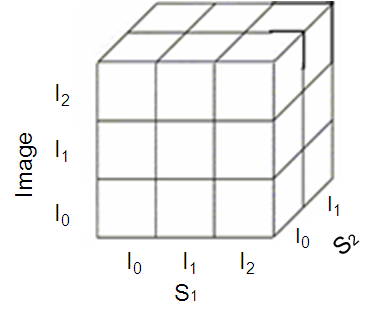 | Figure 5. Image Index Cube. |
2.2. Image Cube Index Model
- An image index cube[4] was proposed. It provides an image view in block vector, codebook and codevector dimensions. A cube index model for image with the image hierarchy and the operations are also defined in[4] as shown in Figure 4. S1 and S2 are the similarity measure based on the codevector or code block or block vector.Vector quantization[18,19,20] is used to quantize and compress the block vectors of pixels of an image. Using the LBG clustering algorithm[21], a codebook is computed for the image. The codebook consists of a set of codevectors that includes some semantic information. It can be used to generate the local codebook[26,27,28]for each image and to generate locally global codebook[30] of the entire set of images. The individual image information is captured in the codebook generated. A global codebook for the entire set of images is generated, using the incremental codebook generation process[30].
2.3. Cube Index for Text and Image
- It is a combination of the text and image cube index model as shown in Figure 6.
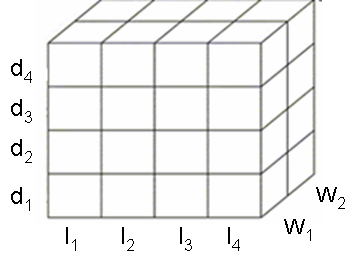 | Figure 6. Cube Index Model. |
2.3.1. Selection
- The document set D where D = {d1,d2,…dn} be a set of n documents. Each document in D contains both images and unstructured text. We select the text and image in the document.
2.3.2. Text Processing
- The text is parsed and preprocessed. The set of content words after preprocessing the document set D is T= {w1,w2,…wm} where wi is the content word. A list of all the content words that make the document collection is used to form the lexicon index. This lexicon index is used to create the word dimension of the cube. Fact is Term Frequency (FT). Let m be total number of words in D, Fij be the number of times the word wi appears in document dj, then Term Frequency FTij = Fij.
2.3.3. Image Processing
- Let I = {i1, i2,…ip} be the set of p images that occur in the document collection D. Each image I is resized to 256 x 256 pixels and converted to 8 bit grayscale image. The image is divided into r block vectors of size b x b. The image block vectors are stored as source vector or training sequence S. For example, consider a 4x4 image as shown below. P1 P2 P3 P4 ----> P1 P2 P5 P6 ----> X1P5 P6 P7 P8 ----> P3 P4 P7 P8----> X2P9 P10 P11 P12 ----> P9 P10 P13 P14----> X3P13 P14 P15 P16 ----> P11 P12 P15 P16 ----> X4Where Pi is the pixel value in an image and Xi is the block vector, then source vector or training sequence S = { X1, X2, X3 …. Xr }. We apply LBG VQ algorithm to S of each image i in I, to find the local codebook CLi for each of the image in the database. CL = {CL1, CL2 ,… ,CLp} where p is the total no of images and each CLi = {Ci1, Ci2, …,Ci256}.(We have used a codebook size of 256 in our experiments).We again consider a training sequence as SLG = {CL1, CL2…CLp} of local codebooks, where each CLi = {Ci1, Ci2, ….Ci256}.Then, we apply the LBG VQ algorithm to SLG, to generate a single codebook CG of size 256 such that CG = {CG1, CG2 ……CG256}This codebook is representative of the content of all the images in the database. We find average distortion Di of all images to the locally global codebook in the database. (Similar images have similar distortion values.)Measure for an image i is calculated as in document j as FIij = Dij .
2.3.4. Cube Index Construction
- Fact of the cube is stored as {FT, FI}. FT is the count of the word w in the document di. If it doesn’t occur, its value is zero. FI is stored only if the image i is present in the document di.
2.3.5. Operations
2.3.5.1. Slice
- The cube can be sliced by word or image as shown in Figures 7 and 8.
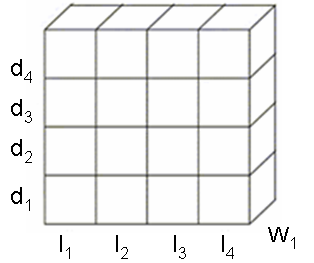 | Figure 7. Word search. |
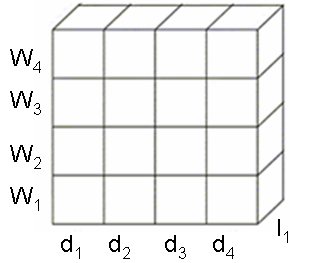 | Figure 8. Image Search. |
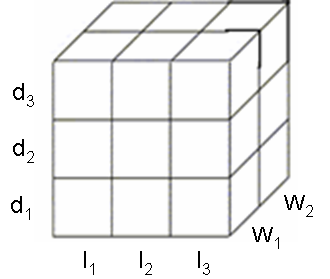 | Figure 9. Dice document collection. |
2.3.5.2. Dice
- The dice operation helps to cluster the group of documents that contain a similar concept as shown in Figure 9. The concept is based on the group of words or content of the images.
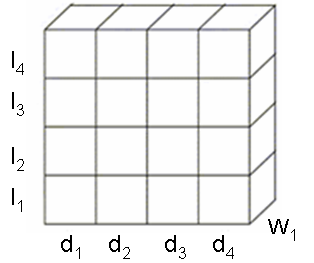 | Figure 10. Pivot image document direct index. |
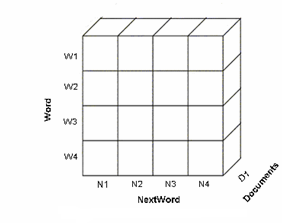 | Figure 11. NextWord Direct Index. |
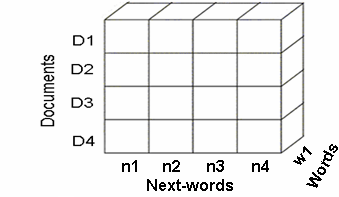 | Figure 12. NextWord Inverted Index. |
2.3.5.3. Pivot
- The pivot operation is used to view the data in different dimensions. It can be used to get the direct index, inverted index and image index view of the cube as shown in Figure 10, 11 and 12. The direct index views the cube based on the document dimension. The inverted index views the cube based on the word dimension. The Figure 11 and 12 gives the view of the direct and inverted index for the text cube index. The image index views the cube based on the image dimension.
2.6. Concept Hierarchy
- Document: A document is represented as a paragraph, sentence, wordpair, and words. It specifies the abstraction of a document representation as shown in Figure 13. It is used for the analysis of words in various levels of abstraction, according to the user needs.Image: It helps to view the image with respect to a codebook, codevector, or pixel block as dimensions as shown in Figure 14.
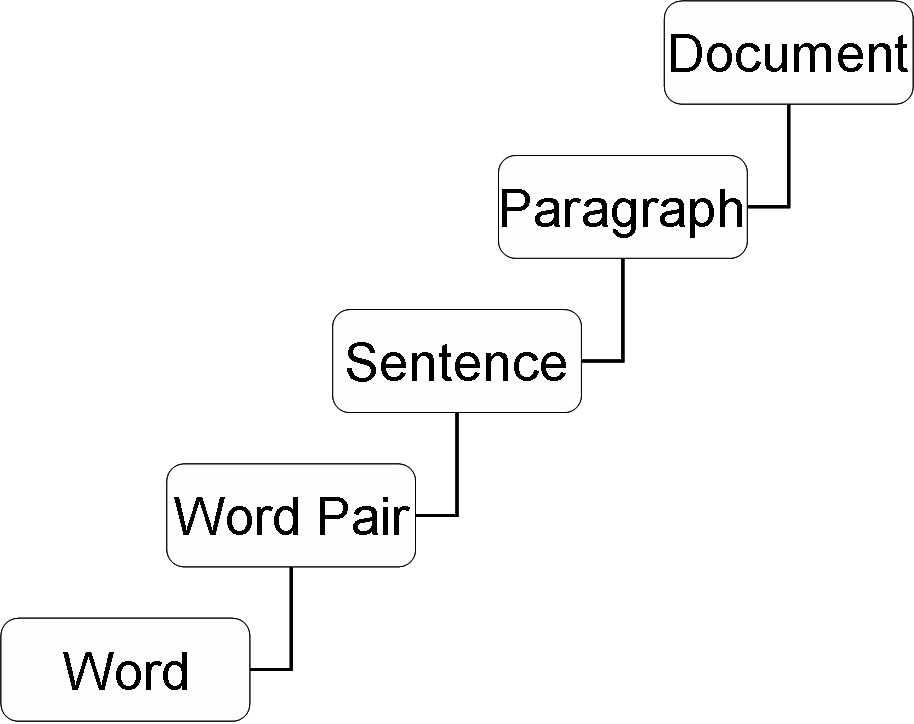 | Figure 13. Concept Hierarchy for a Document. |
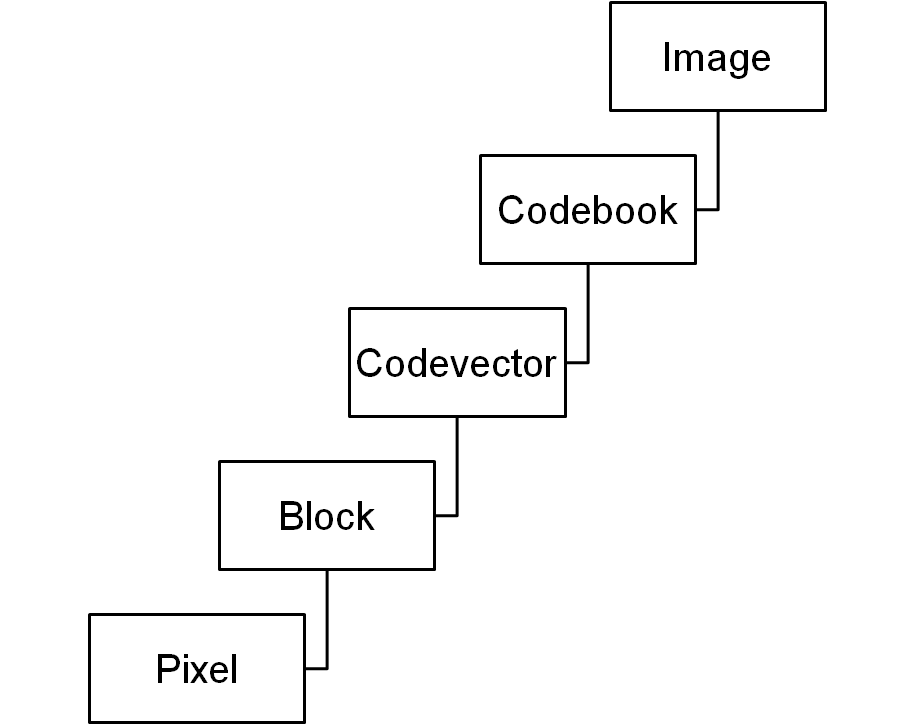 | Figure 14. Concept Hierarchy for an Image. |
2.7. Advantages and Limitations
- The existing index structures for text and image can be used for partial materialization of the cube index. In the cube index, recall increases for the image with a decrease in the precision.The time to build the index is increased as vector quantization is used. The computation needed is more. But this can be overcome by offline processing. The size of the index also matters. But with the reduction in the cost of the memory and the usage of already computed and stored index structures reduce the cost of memory storage. The storage is a sparse index. To reduce the number of words, we do the preprocessing.The cube index is a data cube that can add any number of dimensions to it. Image that occurs in all or most of the documents will be a logo or a header. The applications of the cube index model are annotation, clustering, classification and retrieval of text documents and images.
3. Experimental Results
- The image database from the Department of Computer Science and Engineering, University of Washington, developed for Object and Concept Recognition for Content-Based Image Retrieval[32], is used to create a cube index. The image and its annotation are taken together as a document. If the word occurs in the image annotation then it takes the count of the word as a fact. If the image has no annotation, then the encoding distortion value is taken as the measure of the image and the fact for word is zero. The cube index is materialized for the database.
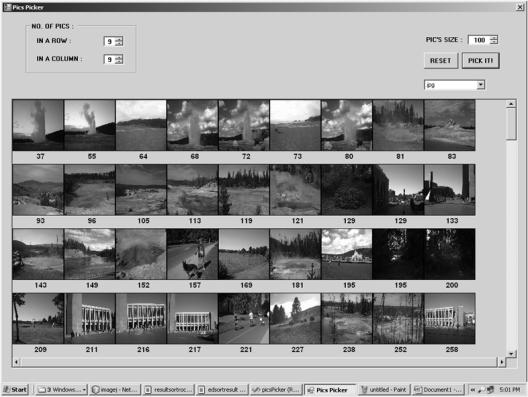 | Figure 15. Word search. |
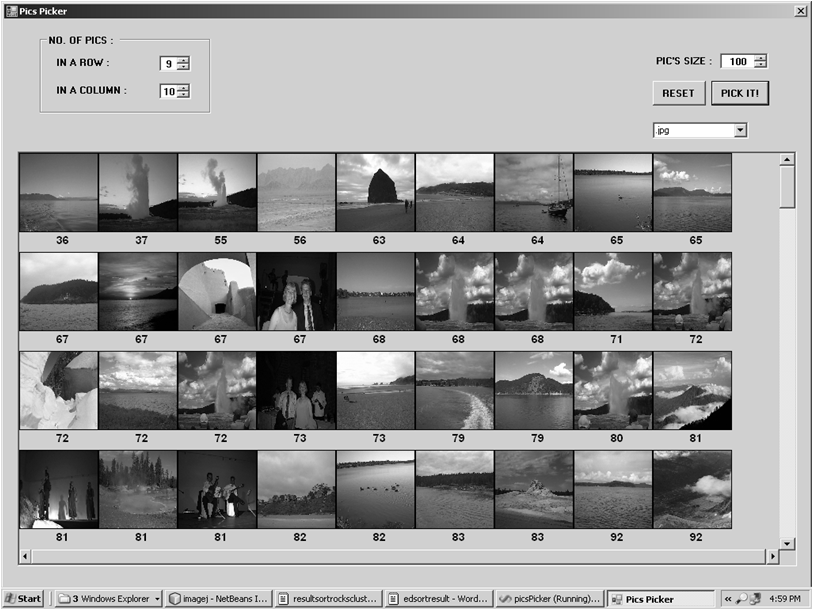 | Figure 16. Cube search. |
4. Conclusions and Future work
- A novel cube index model is proposed in this paper that will help with retrieval of text document, given an image and images present in the document, given a text. The OLAP over the image cube is analyzed based on the performance of the text and image index models proposed earlier. The image hierarchy and some operations for the cube index are also explained. This model can be used on text and image database analysis, retrieval and mining of information. The study shows that text and image are represented with some similarities in their processing in the knowledge discovery process. This has led to the evolution of the cube index model for text, image and combination of both respectively. Using this cube index model, knowledge can be mined by the user according to their need. A complete implementation of the model has to be made to study the performance of the index cube model for large databases. In future, audio data should also be represented as a dimension in the cube structure. A knowledge dimension about the multimedia data must be added to the cube. A weight for the fact in the cell, with different combinations of similarity measures have to be analyzed to increase retrieval accuracy.